







Overview
Respan Gateway is an AI gateway for teams running large language model features in production. Instead of wiring every service directly to separate provider keys, Respan gives developers one gateway endpoint for model routing, provider passthrough, fallback, retries, response caching, spend controls, and automatic logging.
The product is part of Respan's broader LLM engineering platform, which also includes observability, traces, prompt management, evaluations, monitors, and cost tracking. That makes it useful for teams comparing AI agent tools, LLM infrastructure, and production AI observability systems that need more than a simple proxy.
Respan Gateway appeared on Product Hunt's June 11, 2026 daily leaderboard as the #3 launch with the tagline "One AI gateway with built-in observability and evals." Respan's official materials currently use different model-count figures, so this review treats the stable claim as support for hundreds of models through one endpoint.
Key Features
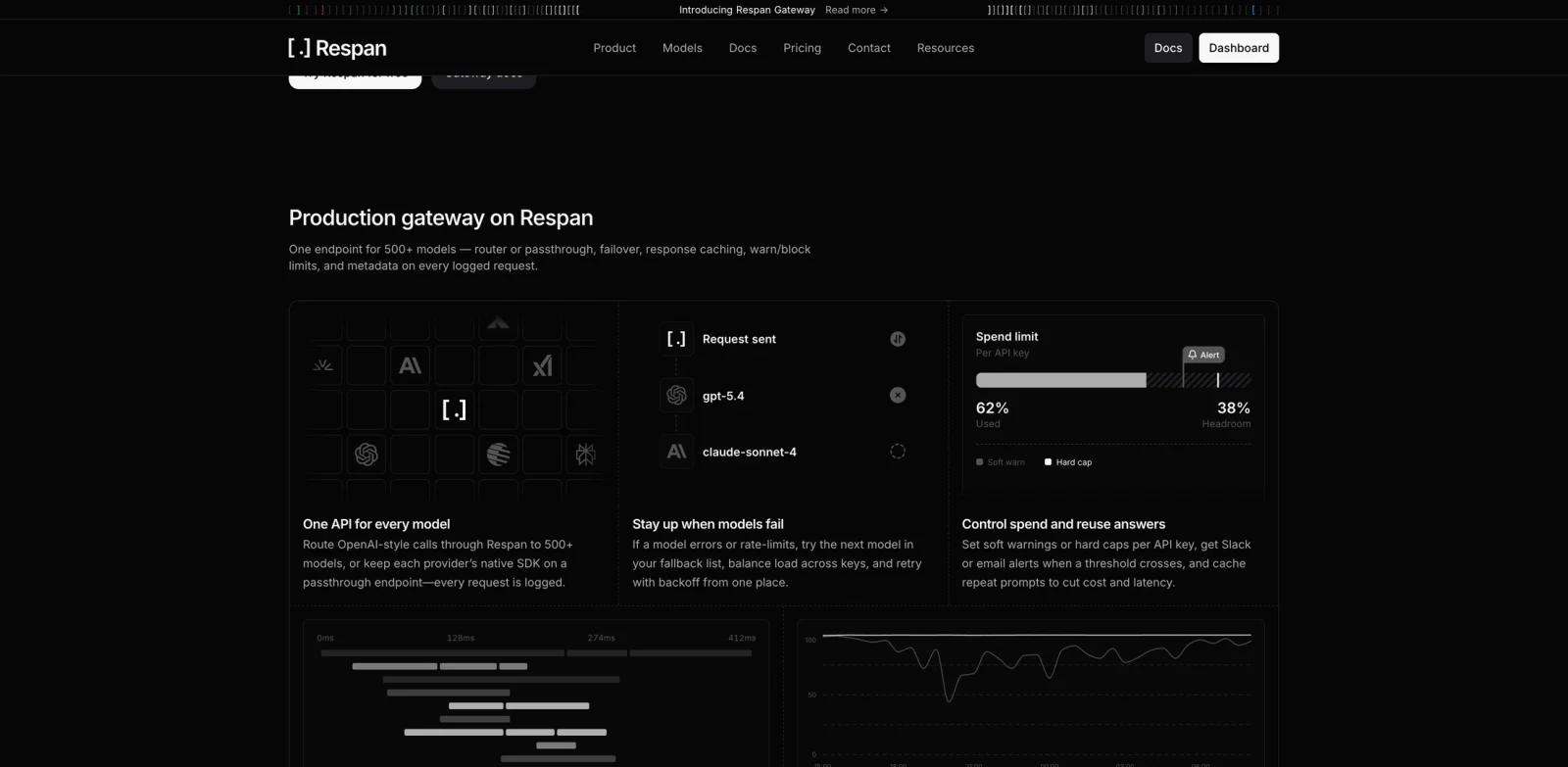
Unified AI gateway endpoint - Route OpenAI-style calls through Respan, or use native passthrough endpoints for providers such as Anthropic and Gemini.
Fallback and retry controls - Configure fallback models, retry behavior, and load balancing so upstream failures or rate limits do not immediately become user-facing errors.
Response caching - Cache repeated prompts to reduce latency and cost, with customer-aware cache controls for multi-tenant applications.
Spend limits and alerts - Set soft warnings or hard caps per API key, then receive Slack or email alerts when usage crosses thresholds.
Trace and log visibility - Every gateway call becomes a trace tree with latency, metadata, customer identifiers, and filters for debugging production behavior.
Evals and prompt management - Use the same platform for datasets, evaluators, prompt versions, and release management instead of stitching together separate tools.
How to Get Started
Respan's gateway quickstart is designed around existing LLM client code. Developers create a Respan API key, add provider credentials or credits, point an OpenAI-compatible client at https://api.respan.ai/api/, then send gateway parameters such as customer_identifier, metadata, fallback_models, and cache options in the request body.
Teams should pilot the gateway on one production path first, especially if they already have custom retry logic. Respan documents configurable gateway retries, fallback, and backoff, but teams should still treat stacked application-level retries as an implementation risk, set explicit retry limits, and verify fallback behavior before full traffic migration.
Pricing & Plans
Respan's official pricing page lists a free Pro tier and paid Team and Enterprise options. The free tier includes the full platform with limits such as 100k logs, 1k scores, 5 datasets, 2 evaluators, and 5 prompts. The Team plan is listed at $199 per month, billed yearly, and includes 5 members, 10k scores, 30-day default retention, 8,400 proxy requests/min, unlimited datasets, unlimited evaluators, unlimited prompts, a private Slack channel, and SOC 2 report access.
| Plan | Price | Notes |
|---|---|---|
| Pro | $0 | Full platform with usage limits, including 100k logs, 1k scores, 5 datasets, 2 evaluators, and 5 prompts |
| Team | $199/month, billed yearly | Includes 5 members, 10k scores, 30-day default retention, 8,400 proxy requests/min, unlimited datasets/evaluators/prompts, private Slack channel, and SOC 2 report access |
| Enterprise | Contact Respan | Custom packages, volume discount, custom SLAs, dedicated support engineer, and HIPAA BAA availability; teams processing PHI should confirm the current BAA and terms during sales/security review |
Gateway-specific limits include proxy throughput, key vault, built-in logging, request caching, auto retries and fallback, load balancing, spend limits, and rate limits. Teams with high log or score volume should check current overage pricing directly on the Respan pricing page.
Best For
- Engineering teams shipping LLM features across multiple model providers
- AI product teams that need fallback, caching, tracing, evals, and spend controls in one workflow
- Startups replacing ad hoc provider-key sprawl with centrally managed gateway keys
- Teams comparing LLM observability tools and AI data governance workflows
- Developers who want OpenAI-compatible routing without building their own gateway infrastructure
FAQ
What does Respan Gateway do?
Respan Gateway routes LLM traffic through one production gateway endpoint. It adds provider passthrough, model routing, fallback, retries, caching, spend limits, alerts, logs, traces, and metadata for every request.
Is Respan Gateway only a model router?
No. Routing is only one part of the product. Respan also includes observability, traces, evals, prompt management, monitors, cost tracking, datasets, and dashboards.
How much does Respan Gateway cost?
Respan has a free Pro tier with usage limits. The Team plan is listed at $199 per month, billed yearly, while Enterprise pricing is custom.
Does Respan support fallback models?
Yes. Respan lets teams set fallback models in platform settings or request parameters so the gateway can try another model if the primary model errors or rate-limits.
Does Respan store request logs?
Respan logs gateway calls by default so teams can inspect logs and traces. The gateway page also mentions options such as disable_log and cache logging controls for teams that need metrics without storing full request and response payloads.
Who should use Respan Gateway?
It is best for teams running production AI applications where uptime, latency, cost, eval quality, and provider reliability matter. A simple prototype that only calls one model may not need this level of infrastructure yet.



