
Sesame AI: Transforming Conversational AI with Natural Voice
Traditional AI voice assistants often sound robotic and lack natural expressiveness. Sesame AI overcomes these limitations with lifelike, context-aware speech generation, creating AI companions that understand, adapt, and engage in real conversations.
By combining advanced speech synthesis, emotional intelligence, and real-time adaptation, Sesame AI delivers more human-like and immersive interactions, setting a new standard for conversational AI. This article explores its key technologies, capabilities, and real-world applications.
An Overview of Sesame AI
Sesame AI is an advanced artificial intelligence company focused on developing lifelike conversational AI that interacts with users in a natural and engaging way. The company envisions a future where AI companions are not just functional but emotionally intelligent, context-aware, and seamlessly integrated into daily life.
At its core, Sesame AI aims to bridge the gap between humans and computers by making digital interactions as intuitive, immersive, and emotionally rich as real conversations. To achieve this, the team is pushing beyond the limitations of traditional voice assistants by creating AI companions that truly understand, engage, and adapt to users over time.
Sesame AI is transforming how we interact with technology through two key innovations: a proactive personal AI assistant and lightweight smart eyewear. The AI assistant goes beyond simple command-based responses, offering real-time, personalized support by recognizing user preferences, moods, and needs. Meanwhile, the wearable AI provides hands-free, context-aware interactions, making digital companionship more natural and immersive. Together, these advancements mark a shift from static, screen-based interfaces to seamless, voice-driven experiences that feel truly human.
How Does Sesame AI Achieve Natural Conversational Voice?
What Is the “Uncanny Valley” in AI Voice?
Sesame AI's approach to crossing the uncanny valley in conversational voice technology
The "uncanny valley" refers to the unsettling feeling people experience when an artificial entity closely resembles a human but falls just short of complete realism. This phenomenon is widely discussed in robotics and computer graphics, but it also applies to AI-generated voices.
In the context of voice AI, the uncanny valley occurs when a digital assistant produces speech that is almost natural but lacks the nuanced emotional and conversational elements that make human interactions feel authentic. AI-generated voices may sound synthetic due to robotic intonations, inconsistent pacing, or a lack of emotional depth, causing users to feel disconnected from the interaction.
What Are the Challenges with Traditional Digital Voice Assistants?
Most existing digital voice assistants, such as those used in smart speakers and virtual assistants, struggle to create meaningful and engaging interactions. Some key limitations include:
- Flat, Neutral Tones – Many AI voice systems rely on text-to-speech (TTS) models that generate spoken output in a monotone voice, making conversations feel unnatural and emotionally disconnected.
- Lack of Context Awareness – Traditional AI assistants process user input in isolation without considering the broader conversation history or emotional tone, leading to responses that may feel out of place or impersonal.
- Limited Expressivity – Human speech is rich in variations of tone, pitch, rhythm, and pauses. Standard AI models struggle to replicate these elements, making them sound less human-like.
- Rigid Interaction Patterns – Most voice assistants operate on predefined commands and responses rather than engaging in dynamic, free-flowing conversations, which limits their usefulness in complex discussions.
These limitations often result in user frustration and a decline in engagement after the initial novelty wears off.
How Does Sesame AI Overcome These Challenges with “Voice Presence”?
Sesame AI introduces a concept called “voice presence”, which aims to make AI-generated voices feel truly natural, engaging, and lifelike. Rather than simply processing and responding to text-based input, Sesame AI is designed to create a genuine sense of interaction by incorporating key aspects of human communication:
- Emotional Intelligence – Sesame AI can detect and respond to the emotional tone of a conversation, adjusting its speech patterns accordingly to sound more empathetic, excited, or reassuring.
- Conversational Dynamics – Unlike traditional TTS systems, Sesame AI models natural timing, pauses, and interruptions to make interactions feel fluid and responsive.
- Context Awareness – By analyzing the history of a conversation, Sesame AI adapts its tone and responses to match the context, ensuring that replies feel appropriate rather than generic.
- Consistent Personality – Instead of sounding like a generic AI assistant, Sesame AI maintains a coherent personality, allowing for more engaging and personalized interactions over time.
What Is the Conversational Speech Model (CSM)?
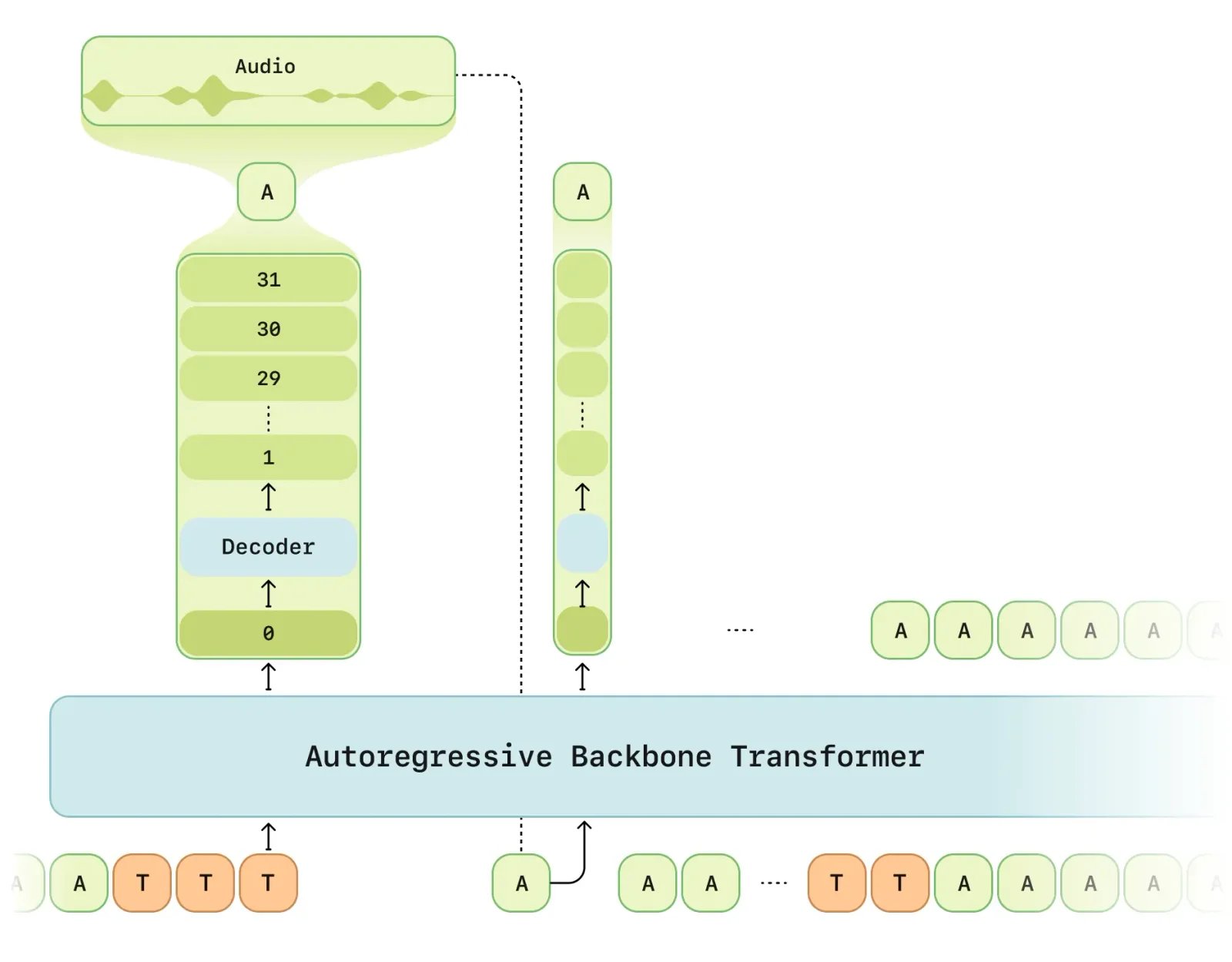
CSM inference process: Interleaved text and audio tokens feed into the Backbone, predicting the codebook's level zero. The Decoder samples remaining levels based on this prediction. Reconstructed audio tokens loop back for the next step until completion. User utterances are represented as interleaved audio-text tokens in subsequent inference cycles.
To achieve this level of realism, Sesame AI utilizes a Conversational Speech Model (CSM) that goes beyond traditional text-to-speech technology. This model operates using multimodal learning, which integrates both text and speech data to generate more natural, context-aware conversations.
1. How Does CSM Improve AI Speech Generation?
Traditional TTS models generate speech by converting written text into spoken words, often in a monotone, rigid manner. CSM, however, is designed to go beyond static text conversion by incorporating:
- Contextual Awareness – Understanding the history of a conversation and adjusting speech accordingly.
- Expressive Speech Synthesis – Generating variations in tone, pitch, and rhythm to make speech more engaging.
- Dynamic Adaptation – Responding to pauses, interruptions, and conversational cues naturally.
By integrating these elements, CSM bridges the gap between AI-generated and human speech, making interactions more fluid, engaging, and lifelike.
2. Key Technologies Behind CSM
CSM leverages multiple cutting-edge AI and speech-processing techniques to enhance voice synthesis.
A. Multimodal Learning for Speech Generation
Instead of relying solely on text inputs, CSM processes both text and speech data simultaneously. This enables the model to retain contextual meaning and generate speech that aligns with conversational intent.
- Text and Speech Integration – Unlike standard TTS, CSM uses interleaved text and audio data for training.
- Conversational Flow Modeling – The model predicts intonation, pauses, and emphasis based on previous dialogue.
B. Semantic and Acoustic Tokenization
To produce high-quality, contextually relevant speech, CSM employs a dual-tokenization approach:
- Semantic Tokens – Capture the meaning and intent behind spoken words, ensuring responses align with conversation context.
- Acoustic Tokens – Preserve intonation, speaker identity, and prosody, making AI speech sound less robotic and more expressive.
This token-based approach allows the model to generate speech that is both semantically accurate and acoustically rich.
C. Residual Vector Quantization (RVQ) for High-Fidelity Speech
To enhance speech clarity and naturalness, CSM utilizes Residual Vector Quantization (RVQ), a method for encoding high-quality audio representations while maintaining computational efficiency.
- Captures Fine-Grained Speech Details – Ensures AI-generated speech retains human-like articulation and rhythm.
- Optimized for Real-Time Processing – Minimizes delay, making conversations feel instant and seamless.
3. Advantages of CSM Over Traditional Speech Models
CSM outperforms traditional TTS models by addressing key limitations in existing AI speech technology.
| Feature | Traditional TTS Systems | Sesame AI’s CSM Model |
|---|---|---|
| Expressiveness | Flat, monotone speech | Emotionally rich, dynamic tone |
| Context Awareness | Limited memory, static responses | Adapts to conversation flow |
| Conversational Timing | Fixed speed, robotic pacing | Natural pauses, emphasis, and rhythm |
| Adaptability | Struggles with diverse situations | Adjusts to mood and speech context |
4. Future Enhancements and Open-Source Collaboration
Sesame AI is committed to improving conversational AI through continuous research and development. Future iterations of CSM will focus on:
- Multilingual Support – Expanding capabilities beyond English for global accessibility.
- Deeper Integration with Pre-Trained Models – Leveraging large-scale AI models for improved contextual understanding.
- Fully Duplex Conversations – Enabling AI to process speech in real-time without delays, allowing simultaneous speaking and listening.
Additionally, Sesame AI has open-sourced key components of CSM, allowing researchers and developers to contribute to its advancement. The project is available on GitHub, encouraging innovation and collaboration in the field of conversational AI.
How Does Sesame AI Ensure Real-Time and Context-Aware Speech Generation?
Real-Time Speech Processing: How Does Sesame AI Minimize Latency?
For AI-driven conversations to feel natural, responses must be generated instantly, without noticeable lag. Sesame AI achieves real-time speech generation through:
- Optimized Speech Models – Sesame AI employs the Conversational Speech Model (CSM), which generates speech in a single-stage process, reducing delays compared to traditional multi-step TTS models.
- Low-Latency Audio Processing – The model uses Residual Vector Quantization (RVQ), which compresses and reconstructs speech efficiently, enabling fast and high-fidelity voice synthesis.
- Streaming-Based Inference – Instead of waiting for full input completion, Sesame AI processes and predicts speech incrementally, allowing for near-instantaneous responses.
These advancements ensure that interactions with Sesame AI feel as smooth and spontaneous as real conversations.
Context Awareness: How Does Sesame AI Maintain Conversational Coherence?
A major limitation of conventional AI assistants is their inability to remember previous interactions or adapt responses based on context. Sesame AI overcomes this through:
- Conversational Memory – The system retains short-term dialogue history, ensuring responses are relevant to the ongoing discussion.
- Dynamic Tone and Style Adaptation – Depending on the conversation’s topic, emotional cues, and speaker intent, Sesame AI modifies its tone to maintain engagement.
- Turn-Taking and Interruptions – The AI understands when to pause, continue, or adjust speech timing to mimic human-like conversational flow.
By incorporating these elements, Sesame AI maintains a sense of continuity and responsiveness across interactions, making conversations feel more human-like.
The Role of Semantic and Acoustic Tokenization in Speech Adaptation
Sesame AI improves real-time conversational accuracy by using dual-tokenization processing:
- Semantic Tokens – Capture the meaning and intent of spoken words, allowing the AI to generate responses that align with the conversation’s context.
- Acoustic Tokens – Preserve intonation, emotion, and speech rhythm, ensuring that AI-generated responses match the speaker’s tone.
This approach allows the AI to interpret and produce speech that is both contextually accurate and emotionally expressive.
How Does Sesame AI Handle Real-Time Conversational Variability?
Natural conversations involve pauses, hesitations, and varying speech speeds, which traditional AI struggles to replicate. Sesame AI enhances realism through:
- Prosody Modeling – Captures variations in pitch, rhythm, and stress, making speech sound less robotic and more expressive.
- Adaptive Speech Generation – Adjusts response length and pacing based on conversational context and user engagement.
- Interruptibility and Response Timing – Unlike traditional systems that wait for a full input before responding, Sesame AI can detect mid-sentence shifts and adjust responses dynamically.
How Does Sesame AI Compare to Other AI Voice Technologies?
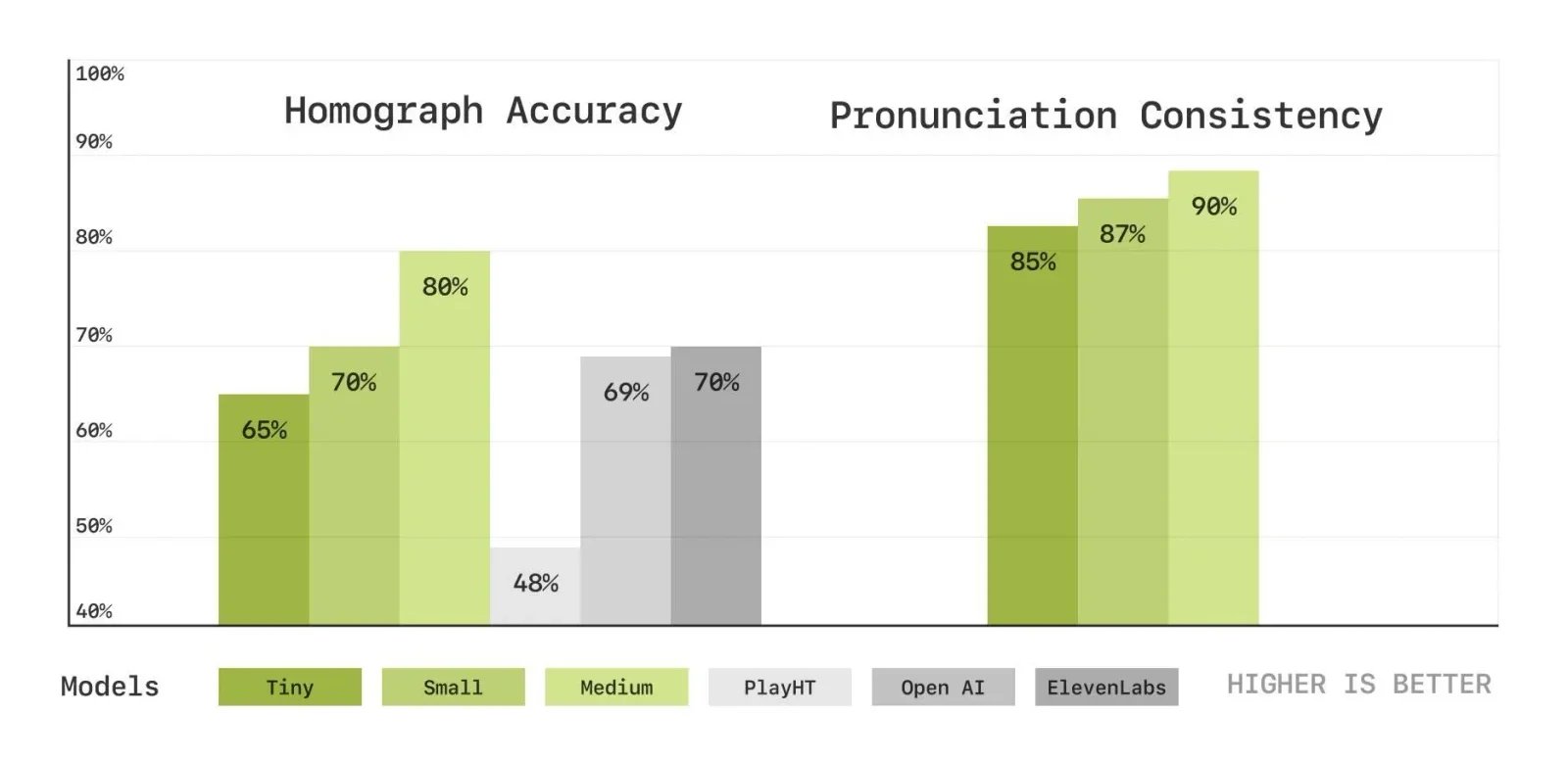
Objective metric results for Homograph Disambiguation (left) and Pronunciation Consistency (right) tests, showing the accuracy percentage for each model's correct pronunciation. Play.ht, Elevenlabs, and OpenAI generations were made with default settings and voices from their respective API documentation.
Benchmarks Against OpenAI, ElevenLabs, and Other TTS Models
AI-generated speech is typically evaluated based on naturalness, expressiveness, context awareness, and real-time performance. Below is a general comparison between Sesame AI’s Conversational Speech Model (CSM) and other popular AI voice technologies.
| Feature | Sesame AI (CSM) | OpenAI TTS | ElevenLabs TTS | Traditional TTS Systems |
|---|---|---|---|---|
| Naturalness of Speech | High – expressive and fluid | High – but sometimes lacks contextual nuance | High – natural-sounding, but less adaptive | Moderate – robotic or flat intonation |
| Context Awareness | Strong – maintains dialogue history | Limited – responses are isolated | Moderate – can adjust slightly based on prior inputs | Weak – each response is independent |
| Expressivity & Emotion | Advanced – models intonation, pauses, and emphasis dynamically | Moderate – improved, but still lacks full emotional adaptation | High – capable of emotional adjustments, but less responsive to context | Weak – lacks emotional variance |
| Real-Time Responsiveness | Optimized – low latency due to single-stage speech generation | Moderate – requires some processing time | High – fast generation, but may lack nuance | Slow – noticeable lag in response times |
| Adaptability to Interruptions | High – can adjust mid-conversation dynamically | Limited – mostly sequential processing | Moderate – some adaptability, but still command-based | Low – strict turn-taking with delays |
| Multimodal Learning | Yes – integrates text and speech for better expressiveness | No – primarily text-based TTS | No – focuses on TTS synthesis only | No – standard text-to-speech pipeline |
Objective and Subjective Evaluation Results
Sesame AI’s Conversational Speech Model (CSM) has been tested using both objective benchmarks and human evaluations.
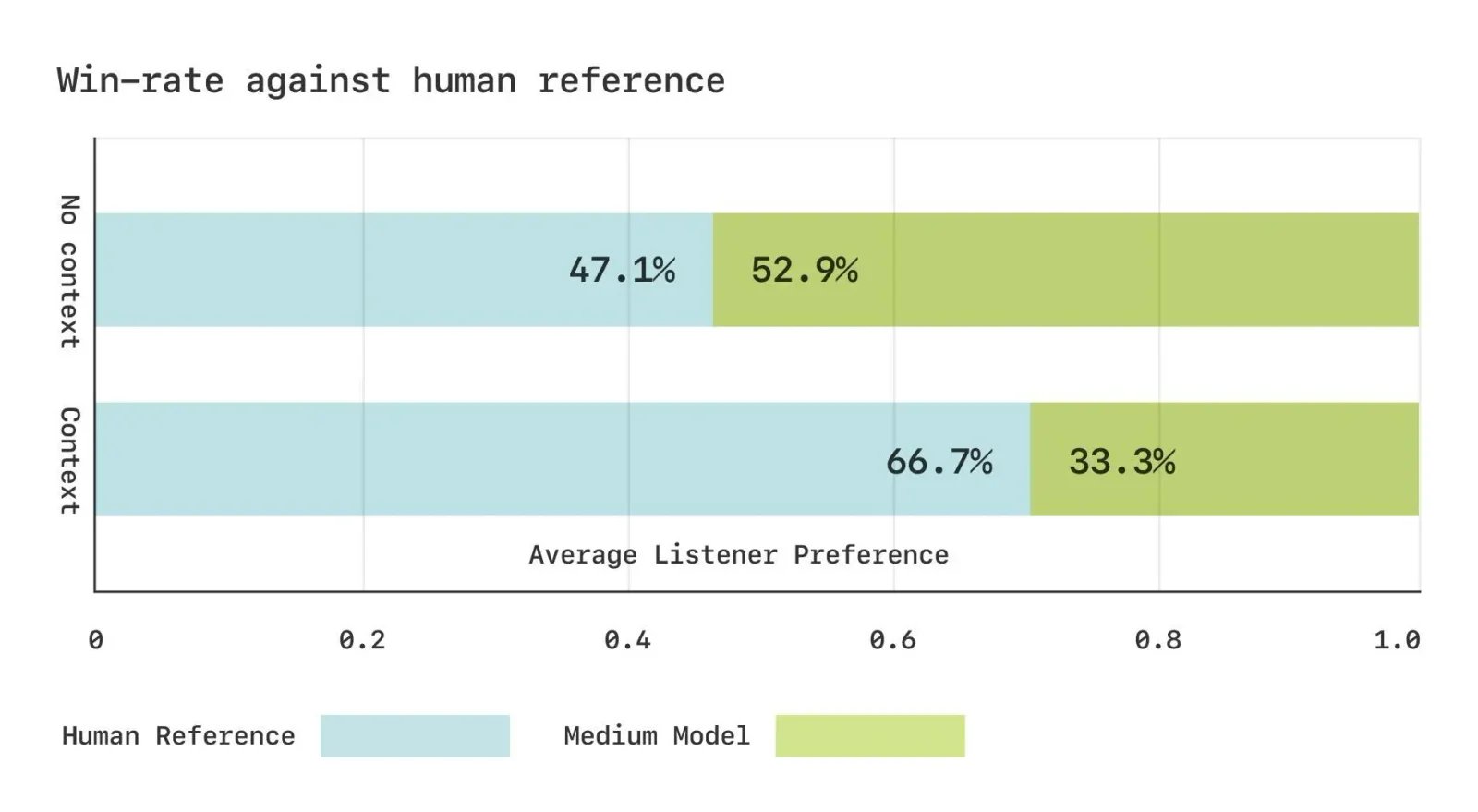
Subjective evaluation results: In the no-context condition, listeners chose "which voice sounds more human"; in the with-context condition, listeners chose "which voice is more appropriate as a continuation of the conversation." A 50:50 win-loss ratio indicates no clear preference between the two by listeners.
Objective Evaluation Metrics
AI voice models are typically evaluated using word error rate (WER), speaker similarity (SIM), and pronunciation accuracy. While OpenAI and ElevenLabs have strong human-like voices, they struggle with contextual understanding and expressivity over long conversations. Sesame AI’s CSM model excels in these areas, demonstrating:
- Lower Word Error Rate (WER) – More accurate pronunciation and contextual speech generation.
- Higher Speaker Similarity (SIM) – More consistent and recognizable voice identity.
- Better Homograph Disambiguation – Distinguishes between words with multiple pronunciations (e.g., “lead” as a metal vs. “lead” as to guide).
Subjective Human Evaluations
To assess naturalness and engagement, a Comparative Mean Opinion Score (CMOS) study was conducted. Participants compared Sesame AI’s CSM with human speech recordings and other AI models. Findings showed:
- Near-Human Expressivity – When played without conversational context, Sesame AI’s speech was rated almost as natural as human speech.
- Superior Contextual Flow – When played with prior dialogue history, users preferred Sesame AI’s responses over OpenAI and ElevenLabs because they felt more coherent and emotionally aware.
- Engagement and Realism – Listeners noted that Sesame AI better captured conversational nuances, such as pauses, tone shifts, and emotional cues.
Advantages of Sesame AI’s CSM Model in Expressivity and Contextual Adaptation
Sesame AI differentiates itself with a focus on natural, adaptive, and expressive voice synthesis, setting it apart from conventional TTS solutions.
A. Advanced Conversational Dynamics
Unlike OpenAI’s and ElevenLabs’ text-to-speech systems, which primarily convert isolated text inputs into speech, Sesame AI’s CSM:
- Maintains conversational memory to ensure continuity.
- Understands and responds dynamically to interruptions, hesitations, and speech patterns.
- Modifies tone based on user interactions to enhance realism.
B. Real-Time Expressivity
CSM incorporates speech rhythm, pitch variation, and pauses naturally, making it more human-like than OpenAI’s standard TTS models. The ability to match conversational pacing and respond dynamically makes Sesame AI’s voice technology feel more natural in real-world applications like customer support, virtual assistants, and interactive storytelling.
C. Multimodal Learning for Speech Adaptation
Sesame AI’s CSM model processes both text and speech data together, unlike traditional TTS systems that rely only on text input. This enables it to:
- Adjust responses based on previous speech patterns.
- Generate more appropriate emotional tones in different conversational contexts.
- Predict and match the speaker’s intent for smoother interaction.
What Are the Limitations and Future Directions for Sesame AI?
Sesame AI has made significant progress in lifelike, context-aware speech synthesis, but it still faces challenges that need to be addressed for broader adoption. Key limitations include multilingual support, real-time responsiveness, data dependency, and ethical concerns. To enhance its capabilities, Sesame AI is focusing on scalability, multilingual adaptability, and AI safety.
Current Limitations
- Limited Multilingual Support – Optimized mainly for English, with inconsistent performance in other languages and dialects.
- Real-Time Adaptability – Struggles with fully duplex conversations, longer context retention, and natural interruption handling.
- Data Dependency – Requires large, high-quality datasets, posing challenges in diversity, bias reduction, and computational efficiency.
- Ethical Concerns – Risks of voice cloning misuse, bias in speech models, and privacy issues demand stronger safeguards.
Future Directions
- Multilingual Expansion – Enhancing support for 20+ languages, improving intonation, accents, and cultural adaptability.
- Fully Duplex Conversations – Refining real-time response timing, interruption detection, and turn-taking dynamics.
- Efficient AI Deployment – Reducing computational cost and enabling on-device speech processing for improved privacy.
- Stronger AI Ethics – Implementing voice authentication, bias detection, and transparency measures to ensure responsible AI use.
How Can Developers and Researchers Contribute to Sesame AI?
Open-Source Initiatives and Community Collaboration
Sesame AI has open-sourced key components of its research to foster transparency, innovation, and accessibility. By making its technology publicly available, the company encourages contributions in:
- Enhancing Speech Models – Improving expressivity, multilingual support, and real-time responsiveness.
- Optimizing Computational Efficiency – Reducing latency and resource requirements for broader accessibility.
- Expanding Conversational AI Applications – Integrating CSM into assistive technologies, virtual agents, and interactive AI systems.
Availability Under Apache 2.0 License
Sesame AI’s Conversational Speech Model (CSM) is released under the Apache 2.0 license, allowing developers to:
- Freely use, modify, and distribute the code.
- Integrate it into commercial and non-commercial applications without restrictive limitations.
- Contribute back to the project by submitting improvements and enhancements.
This open licensing model ensures broad accessibility while maintaining flexibility for enterprise and research applications.
How to Get Involved?
Developers and researchers can contribute to Sesame AI by engaging with its GitHub community and participating in research collaborations:
- Explore the GitHub Repository – Access the source code, documentation, and research updates at SesameAI GitHub.
- Submit Contributions – Improve existing models, propose new features, and optimize performance through pull requests.
- Engage in Discussions – Join the GitHub Issues and Discussions section to share insights, report bugs, and propose enhancements.
- Collaborate on Research – Sesame AI actively partners with academic institutions and AI researchers to explore advancements in natural speech synthesis.
What Are the Potential Applications of Sesame AI in Daily Life?
1. Personal AI Assistants
Sesame AI can serve as a smart, voice-driven assistant that helps users manage daily tasks, such as:
- Scheduling and Reminders – Providing timely alerts and organizing tasks based on user preferences.
- Information Retrieval – Offering summaries of news, emails, and real-time updates in a conversational format.
- Personalized Coaching – Assisting with productivity, language learning, and personal development through interactive conversations.
2. Smart Home and IoT Integration
With its context-aware speech capabilities, Sesame AI can enhance smart home systems by enabling:
- Voice-Controlled Automation – Adjusting lighting, temperature, and security settings through natural dialogue.
- Contextual Device Interaction – Adapting responses based on user habits and environmental conditions.
- Multi-User Personalization – Recognizing different household members and tailoring interactions accordingly.
3. Accessibility and Assistive Technology
Sesame AI’s expressive voice generation makes it an ideal solution for accessibility, including:
- Assistive Communication – Helping individuals with speech impairments by converting text into natural, expressive speech.
- AI-Powered Companions – Providing conversational support for elderly users and individuals with cognitive disabilities.
- Real-Time Transcription and Summarization – Enhancing accessibility for those with hearing impairments by converting spoken language into text.
4. Customer Support and Virtual Agents
Businesses can integrate Sesame AI into customer service systems for more engaging, efficient, and human-like interactions, such as:
- Conversational AI Chatbots – Offering personalized, real-time support with adaptive voice responses.
- Automated Call Centers – Reducing wait times by handling complex, multi-turn conversations with natural expressiveness.
- Emotional AI for Customer Engagement – Detecting customer sentiment and adjusting tone accordingly.
5. Education and Interactive Learning
Sesame AI’s real-time adaptability and expressive voice synthesis make it an excellent tool for learning and training environments, including:
- AI Tutors and Language Assistants – Providing personalized lessons and real-time pronunciation feedback.
- Immersive Storytelling – Bringing books and lessons to life with natural, dynamic narration.
- Hands-Free Learning – Enabling interactive, voice-based education for students with disabilities.
6. Entertainment and Content Creation
Sesame AI can be used to enhance digital media and entertainment by powering:
- Lifelike Virtual Characters – Enabling realistic voiceovers for video games, films, and virtual reality experiences.
- AI-Powered Podcast and Audiobook Narration – Generating expressive and engaging voiceovers.
- Interactive Voice Companions – Providing engaging storytelling and role-playing interactions.
Frequently Asked Questions (FAQ)
What Makes Sesame AI Different from Existing AI Voice Assistants?
Sesame AI stands out from traditional AI voice assistants through its advanced conversational speech model (CSM), emotional intelligence, and real-time contextual adaptation. Unlike standard TTS-based assistants, Sesame AI focuses on:
- Voice Presence – Generates speech with natural intonation, dynamic pauses, and expressive tone, making conversations feel more human-like.
- Context Awareness – Maintains conversational memory, allowing it to track previous exchanges and adapt responses accordingly.
- Real-Time Expressivity – Uses semantic and acoustic tokenization to adjust speech rhythm, emphasis, and emotional cues dynamically.
- Interruptibility and Turn-Taking – Handles natural pauses and interruptions smoothly, creating fluid, interactive conversations.
- Low-Latency Processing – Optimized for fast response times, making interactions more seamless compared to traditional AI assistants.
By combining expressive speech generation, contextual adaptation, and emotional intelligence, Sesame AI delivers a more immersive and lifelike conversational experience than existing AI voice technologies.
What Is “Voice Presence” and Why Is It Important?
Voice presence refers to an AI’s ability to generate speech that feels genuine, expressive, and contextually aware, making interactions more natural and engaging. Unlike traditional AI voices that sound robotic or monotonous, Sesame AI’s voice presence incorporates:
- Emotional Intelligence – Detects and responds to tone, pitch, and speech rhythm to convey emotions.
- Conversational Awareness – Adapts to pauses, interruptions, and user intent for a more fluid dialogue.
- Consistent Personality – Maintains a coherent and engaging voice identity across interactions.
Why Is Voice Presence Important?
- Enhances User Engagement – More realistic and dynamic speech improves human-AI interaction.
- Builds Trust and Connection – Expressive AI speech fosters a sense of understanding and reliability.
- Improves Usability – Makes AI assistants more intuitive and enjoyable in daily applications.
What Datasets Are Used to Train Sesame AI’s Voice Models?
Sesame AI’s voice models are trained on a large-scale dataset of publicly available audio, which has been transcribed, diarized, and segmented to ensure high-quality training data. The dataset primarily consists of:
- Public Speech Data – High-quality recordings of diverse speakers to enhance natural expressiveness and voice variation.
- Conversational Audio – Dialogue-based datasets to improve context awareness, turn-taking, and adaptive responses.
- Phonetically Rich Speech – A wide range of accents, intonations, and prosodic variations for better pronunciation and emotional depth.
To maintain privacy and ethical AI development, Sesame AI does not use private or unauthorized data, and its models are evaluated for fairness and bias reduction.
Get ToolWorthy Weekly
New AI tools, practical guides, and selected AI signals in one weekly brief.
Discover More AI Tools
Explore our comprehensive directory of AI tools, carefully curated and reviewed by experts to help you find the perfect solution for your needs.