
10 Best Llama Alternatives 2026 - Open Models, APIs, and Safer Migration Paths
Llama is still one of the most important open-weight model families in AI. That is exactly why it should not be treated as the automatic default anymore.
By June 2026, the decision has split into smaller, harder questions. Do you want the cheapest hosted API, the cleanest commercial license, the strongest local coding model, a European enterprise vendor, a fully open research stack, or a model you can run on a laptop without turning inference into a hardware project? A r/LocalLLaMA user reduced the mood to three words: "literally only two". That was not a full benchmark, but it captured how often Qwen and DeepSeek now come up when people ask what to run next.
This guide is for teams comparing alternatives to Llama as a production bet, not for people looking for a generic chatbot ranking. Some options below are direct open-weight replacements. Some are hosted APIs that replace the work of operating Llama. Some are adjacent managed platforms that are better when model ownership is less important than procurement, reliability, or product quality. If your real search is broader than LLM infrastructure, keep a separate shortlist of AI chatbots and AI agent tools; those categories answer product-buying questions that model-family comparisons cannot.
| Tool | Best For |
|---|---|
| DeepSeek | Lowest-friction long-context API economics |
| Qwen | Apache-licensed local and multilingual deployments |
| Mistral AI | European enterprise and mixed open/hosted stacks |
| Google Gemma | Local, edge, and Gemma Terms-reviewed deployments |
| Kimi | Frontier-scale open-weight agent experiments |
| Microsoft Phi | Compact local reasoning and device-side apps |
| AI2 OLMo | Fully open research and auditability |
| GLM / Z.ai | Diversifying beyond Meta, Qwen, and DeepSeek |
| OpenAI GPT-OSS | U.S. vendor ecosystem with open-weight options |
| NVIDIA Nemotron | Optimized enterprise inference on NVIDIA infrastructure |
Why People Are Leaving Llama in 2026
These are not six reasons Llama is bad. Llama remains capable, widely supported, and easy to find through inference providers, Hugging Face, local runners, and cloud marketplaces. The point is narrower: the reasons to leave Llama have become specific enough that "use Llama by default" can now be the lazy answer.
1. Qwen became a practical default in many local-model conversations, while DeepSeek changed the hosted-API cost discussion. In local AI communities, the question often shifted from "Which Llama quant should I run?" to "Which Qwen variant should I test?" A June 2026 r/LocalLLaMA thread framed the choice as "literally only two". Another user said a new Qwen release "completely shocked me". DeepSeek belongs in the same Llama-alternative discussion, but mainly because its hosted API pricing and long-context models can make self-hosting look less compelling.
2. Hosted API economics make self-hosting harder to justify. The old argument for Llama was simple: download weights, run them yourself, avoid frontier API bills. That still works when offline control, fine-tuning, or data residency is the reason. It is weaker when the real workload is a high-volume hosted agent. DeepSeek's official pricing page lists DeepSeek V4 Flash at $0.14 per million cache-miss input tokens and $0.28 per million output tokens, with V4 Pro listed at $0.435 and $0.87 respectively as of June 8, 2026. Reddit cost threads keep asking why teams would buy or rent GPUs when an API bill can be that low, with one post saying the price was "unreal".
3. Running Llama locally is still a hardware project. Local inference is liberating only after the GPU, VRAM, quantization, context, serving, monitoring, and latency problems are solved. One r/LocalLLaMA user captured the fragility of that setup by noting that one person's experience can be "completely ruined by a IQ2 quant". That is not a knock on quantization. It is a reminder that self-hosting Llama is not the same as using a product. If your team does not already know how it wants to trade context length against quality and token speed, a hosted model or a smaller local family may be the better migration path.
4. Open-weight is not open-source enough for some legal teams. Meta's official Llama 4 Community License grants broad rights, but it is still a custom license with attribution, acceptable-use, termination, and large-user commercial terms. A Hacker News commenter framed the confusion as a mismatch between marketing and legal language. Another thread complained that the licensing was "such a mess". You do not need to agree with the tone to see the risk. If legal, compliance, or downstream customers demand a standard permissive license, start with exact Apache/MIT candidates such as Qwen, Mistral 3, Phi, OLMo, GLM/Z.ai, and OpenAI GPT-OSS. Keep Gemma in a separate review lane because Gemma models use Google's Gemma Terms rather than a standard Apache/MIT license.
5. EU and multimodal licensing risk can complicate deployment. The Llama 4 use-policy language for multimodal models says the license rights are not granted to an individual domiciled in, or company principally based in, the European Union; the same clause says this restriction does not apply to end users of a product that incorporates such models. That nuance matters. It is not a universal "no EU user can ever touch it" rule, but it is enough to slow architecture decisions. The r/LocalLLaMA discussion quoted the same clause and stressed that it was about multimodal models, while Axios had already reported Meta's stated plan to withhold future multimodal Llama models from EU customers because of regulatory uncertainty.
6. Meta's roadmap looks more hybrid than reliably open. Llama 4 Scout and Maverick shipped as open-weight models, and Meta's official GitHub model table lists Llama 4 with Scout and Maverick variants, 10M and 1M context lengths, and the Llama 4 license. But teams building long-lived products care about the next release, not just the current one. Axios reporting in 2026 described Meta's future model strategy as more mixed, with open versions expected for some models while the strongest internal systems could remain proprietary. The practical lesson is not "avoid Meta." It is "do not make Meta the only supplier your product can use."
There are also good reasons not to leave. Llama still has one of the strongest ecosystems around local runners, cloud providers, model cards, tutorials, fine-tunes, and production examples. If your team already has a stable Llama stack, passing evals, acceptable legal review, and predictable serving cost, migration should be justified by a real business reason, not community fashion. The most expensive mistake in model strategy is replacing a working baseline with a model that looks better in a benchmark but fails in your retrieval pipeline, safety policy, latency budget, or procurement process.
The cleaner framing is "second supplier," not "replacement." Add DeepSeek if the API math is compelling. Add Qwen if local model momentum and Apache-licensed releases matter. Add Mistral if European vendor posture matters. Add OLMo if auditability matters. Keep Llama as the regression baseline until the alternative beats it on the tasks your users actually perform.
These six pain points map to six decisions: API cost, local momentum, hardware burden, license simplicity, regional risk, and vendor roadmap. The best Llama alternative is the one that solves your actual decision, not the one with the loudest benchmark chart this week.
Before you choose, write the reason in one sentence. "We want a better model" is too vague. "We need an Apache-licensed local coding model our legal team can approve" points toward Qwen, Mistral, OLMo, or Gemma. "Our GPU plan costs more than our expected inference bill" points toward DeepSeek or a hosted open-model provider. "We need to ship in Europe with less ambiguity" points toward Mistral and careful license review. "We need to audit data and training process" points toward OLMo. This one-sentence diagnosis prevents the classic migration failure: picking a model that is impressive for someone else's constraint.
Also separate model quality from system quality. Llama may be worse than a competitor on one prompt and still better in your application because your retrieval chunking, prompt templates, tool schemas, safety filters, and caches have been tuned around it. The inverse is also true: a model that looks only slightly better in isolated evals can unlock a simpler product if it removes a license review, a GPU queue, or a vendor-risk exception.
Top 10 Llama Alternatives Compared
The table ranks the 10 detailed alternatives first, then adds five managed honorable mentions so you can see the whole decision environment in one place. Scores are deliberately conservative. In this market, a 9.5 usually says more about marketing than production fit.
| Tool | Access Model | License / Control | Best Switching Reason | Migration Effort | Score |
|---|---|---|---|---|---|
| Llama | Open weights plus cloud partners | Llama Community License | Strong baseline and ecosystem | None | Baseline |
| DeepSeek | Hosted API plus open releases | Mixed open/API terms | Very low API cost and 1M context | Low | 8.8 |
| Qwen | Open weights plus hosted routes | Apache 2.0 on key releases | Local coding, multilingual, permissive use | Medium | 8.7 |
| Mistral AI | Open models, hosted API, enterprise | Apache 2.0 on Mistral 3; commercial tiers vary | European vendor and enterprise deployment | Medium | 8.5 |
| Google Gemma | Open models and Google ecosystem | Gemma Terms; not Apache/MIT, so review version-specific terms | Local, edge, and Google-native experiments | Low | 8.4 |
| Kimi | Open-weight MoE plus API routes | Modified MIT on Kimi K2; verify the exact release | High-ceiling agent experiments | High | 8.2 |
| Microsoft Phi | Compact open-weight models | MIT on Phi-4-mini-instruct; verify the exact Phi release | Device-side reasoning and small models | Low | 8.1 |
| AI2 OLMo | Fully open weights, data, code, recipes | Apache 2.0 on core OLMo 2 releases; check instruct-model data notes | Reproducible research and auditability | High | 8.0 |
| GLM / Z.ai | Open and hosted model family | MIT on recent GLM-5 / GLM-5.1 releases | Supplier diversity and coding agents | Medium | 8.0 |
| OpenAI GPT-OSS | Open-weight route plus OpenAI ecosystem | Apache 2.0 plus OpenAI gpt-oss usage policy | U.S. vendor ecosystem and familiar tooling | Medium | 7.9 |
| NVIDIA Nemotron | Open models plus optimized serving | NVIDIA Open Model License; NIM requires NVIDIA AI Enterprise | NVIDIA enterprise inference stack | Medium | 7.9 |
| Claude | Hosted API and apps | Managed proprietary | Reasoning, writing, coding quality | Low | Managed mention |
| Gemini | Hosted API plus Google AI ecosystem | Managed proprietary; Gemma for open models | Multimodal and long-context managed workflows | Low | Managed mention |
| Cohere Command | Hosted enterprise model platform | Managed commercial | RAG and enterprise retrieval | Low | Managed mention |
| Together AI | Hosted open-model inference | Provider terms plus model terms | Avoid owning GPUs while using open models | Low | Managed mention |
| Fireworks AI | Hosted open-model serving | Provider terms plus model terms | Fast serving route for open weights | Low | Managed mention |
Detailed Reviews
DeepSeek
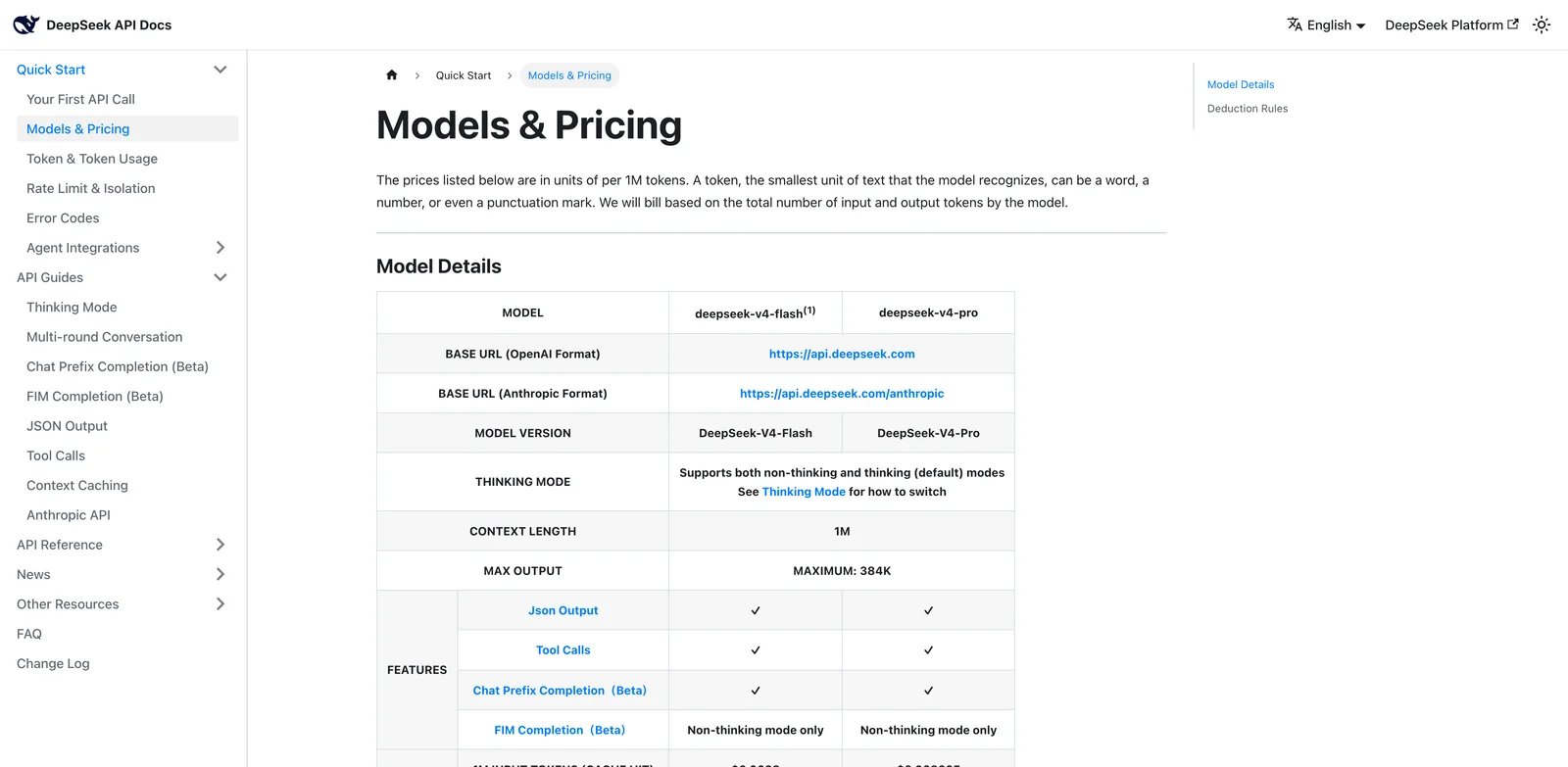
DeepSeek is the first Llama alternative to test when the real problem is cost. The number that changes the conversation is not a benchmark score; it is the official V4 price table. As of June 8, 2026, DeepSeek's pricing page lists a 1M-token context length for V4 Flash and V4 Pro, OpenAI-format and Anthropic-format base URLs, tool calls, JSON output, and extremely low per-token pricing.
What DeepSeek solves vs Llama: The API math: DeepSeek can make the "we should run Llama ourselves" plan look expensive once you price in GPUs, uptime, engineering time, monitoring, and eval maintenance. It also reduces migration friction because many apps can point an OpenAI-compatible client at the DeepSeek base URL and run a measured trial without redesigning the product. If your current Llama deployment powers agents, evaluate DeepSeek beside your existing AI agent stack instead of only testing raw chat completion quality.
Pricing vs Llama: Llama weights can be free to download, but the real cost is infrastructure. DeepSeek charges per token. That makes it easier to model usage spikes, route cheap workloads to Flash, and keep Pro for harder reasoning or agent runs. The tradeoff is vendor review, not hardware purchase.
Limitations: DeepSeek is not the lowest-risk vendor for every organization. Security review, regional policy, data handling, and procurement may matter more than price. Also, hosted API economics can change, so teams should check the official pricing page before committing architecture.
The best DeepSeek evaluation is boring and numerical. Pick 200 representative tasks, run them through Llama and DeepSeek, and score each output by completion, tool-call validity, citation behavior, latency, and final cost. DeepSeek wins when it completes the same work with less operational overhead. It loses when governance, output quality, or routing complexity erases the token-price advantage.
Best for: DeepSeek is best for agents, long-context document workflows, cost-sensitive internal copilots, and teams that do not need to own the serving stack. Not the right fit if your requirement is offline inference, strict vendor geography, or full control over weights and fine-tuning.
Get started with DeepSeek.
Qwen

Qwen is the closest thing to a community-default Llama replacement for many local model users in 2026. The pitch is not only "Alibaba has strong models." The pitch is license plus momentum: key Qwen model cards and artifacts use Apache 2.0, the local community talks about Qwen constantly, and the family covers small, coding, multimodal, and multilingual use cases.
What Qwen solves vs Llama: License plus momentum: Qwen gives teams a path where the model conversation can be both practical and legally simpler. If your legal team wants Apache 2.0 language and your engineers want a model that local runners, quantization communities, and coding-agent users are actively testing, Qwen deserves an early slot in the eval. The Qwen3-30B-A3B-GGUF license is a useful starting example for the Apache 2.0 pattern, though you should still verify the exact model you plan to ship. ToolWorthy also tracks current Qwen product coverage, including Qwen3.5 and smaller on-device variants.
Pricing vs Llama: Like Llama, Qwen can be free at the weight level and expensive at the infrastructure level. The strongest comparison is not subscription versus subscription; it is license simplicity plus local performance versus Llama ecosystem maturity. Hosted providers can reduce the operational cost if you do not want to self-serve.
Limitations: Qwen is not one single product. You need to choose the exact size, quantization, context, and deployment path. Large or MoE variants can still be hard to run well, and some enterprises will run additional vendor risk review because of Alibaba's origin.
Qwen is strongest when the migration goal is practical local capability. Do not judge it only by one online leaderboard. Test it with your own prompts: codebase Q&A, multilingual customer messages, structured JSON, retrieval summaries, and refusal-sensitive examples. If a smaller Qwen variant beats your current Llama setup with lower latency, the switch can be easier to defend than a move to a heavier model with a higher headline score.
Best for: Qwen is best for local coding, multilingual apps, research prototypes that may become commercial, and teams that want an Apache-licensed model family before a custom-license family. Not the right fit if your procurement process cannot approve the vendor or if your workload is better solved by a cheap hosted API.
Get started with Qwen.
Mistral AI
Mistral AI is the Llama alternative for teams that want open models without giving up the enterprise route. It is also the cleanest answer when a European vendor story matters. The company now spans open model releases, hosted APIs, enterprise services, and model customization, so it can replace Llama at different layers of the stack.
What Mistral AI solves vs Llama: EU procurement angle: Mistral gives procurement and legal teams a European AI lab to evaluate instead of only U.S. and Chinese vendors. Its current model overview lists open and premier models across general, specialist, transcription, OCR, and code use cases. Its Mistral 3 announcement says Mistral Large 3 and the Ministral 3 family were released under Apache 2.0, while enterprise customers can still use hosted and custom routes.
Pricing vs Llama: Mistral can look more expensive than raw Llama weights if you only count download cost. It can look cheaper if the alternative is building a full serving platform, handling EU procurement alone, and stitching together support contracts across multiple providers.
Limitations: Mistral's catalog mixes open and premier models, and older/specialist models can have different license terms. You need to verify the exact model, deployment mode, and commercial rights before presenting it as an Apache 2.0 replacement.
Mistral's best fit is usually organizational rather than purely technical. A startup may choose Qwen or DeepSeek because the eval is fast and cheap. A mid-market or enterprise buyer may choose Mistral because the internal conversation includes procurement, support, EU data posture, cloud availability, and executive comfort with the vendor. That does not make the model better in every prompt; it makes the deployment path easier to defend.
Best for: Mistral AI is best for European teams, regulated buyers, multilingual enterprise products, and companies that want both open weights and a serious hosted/vendor path. Not the right fit if you only want the cheapest possible API or the biggest local hobbyist community.
Get started with Mistral AI.
Google Gemma
Gemma is the Llama alternative for teams that do not need a huge flagship model to solve a small local problem. Google positions Gemma 3 as a family of lightweight open models built from Gemini research and suited for laptops, desktops, and cloud infrastructure with limited resources.
What Google Gemma solves vs Llama: Small-model reality: The official Gemma 3 model card highlights multimodal text-and-image input, 128K context for 4B, 12B, and 27B sizes, and multilingual support across more than 140 languages. For many product teams, that footprint is more useful than trying to fit a larger Llama model into a constrained environment.
Pricing vs Llama: Gemma and Llama can both be weight-level options, but Gemma's advantage is often operational. Smaller models reduce VRAM pressure, speed up iteration, and make laptop or edge tests less painful. Hosted Google routes may be more expensive than local inference but easier to approve if the organization already uses Google Cloud.
Limitations: Gemma licensing has changed across generations and model variants, so do not assume every Gemma release carries the same terms. Gemma is also not a general replacement for the largest open-weight or hosted frontier models when your workload needs maximum reasoning depth.
Gemma is especially useful when "good enough and easy to run" beats "largest possible." Many Llama migrations fail because teams compare their ideal model to their real deployment. A smaller Gemma model that runs reliably on available hardware can outperform a larger Llama plan that depends on aggressive quantization, long queues, or fragile serving assumptions.
Best for: Gemma is best for edge apps, classroom or prototyping environments, Google-native teams, and builders who want a strong small model before reaching for a giant MoE. Not the right fit if your main requirement is full training-data transparency or a Llama-sized flagship.
Get started with Google Gemma.
Kimi
Kimi is the high-ceiling, high-friction alternative. The appeal is obvious: Moonshot's Kimi K2 line pushed open-weight MoE models into frontier-scale agent conversations. The caution is just as obvious: large MoE models are infrastructure decisions, not casual drop-in swaps.
What Kimi solves vs Llama: Kimi is interesting when your team wants to test whether a very large open-weight agent model can replace a Llama-based architecture for coding, tool use, long-context planning, or autonomous workflows. It belongs in the eval when the question is "How far can open weights go?" rather than "What is the easiest model to deploy?"
Pricing vs Llama: At the weight level, Kimi can be attractive if the license fits. At the runtime level, it can be expensive because frontier-scale MoE models demand serious memory, bandwidth, and serving work. Hosted routes may be the practical way to evaluate it before any self-hosting plan.
Limitations: Verify the exact Kimi release, license, weight availability, and provider terms. Modified MIT-style licenses and community mirrors are not the same as a procurement-ready enterprise contract. Model size can also make local evaluation misleading if you only test a heavily quantized build.
Kimi should be evaluated with agent tasks, not only chat prompts. Give it multi-step coding, browser, tool-use, and planning workloads where a large MoE model can show a real advantage. ToolWorthy's current coverage of Kimi K2.5 is a useful place to track the model family as it changes.
Best for: Kimi is best for advanced labs, coding-agent teams, and organizations that can afford serious inference engineering. Not the right fit if your team wants a boring, cheap, easy Llama replacement this week.
Get started with Kimi.
Microsoft Phi
Phi is not trying to be Llama with a different logo. Its reason to exist is compact reasoning. If your migration question is "Can we do this on smaller hardware?" Phi deserves attention before you spend weeks compressing a larger Llama model into a shape it was not designed for.
What Microsoft Phi solves vs Llama: Phi gives teams a small-model path for local reasoning, education, device-side experiments, and Windows or Azure-adjacent workflows. The Phi technical reports have consistently emphasized compact model design rather than brute-force parameter count, which makes the family useful for constrained environments.
Pricing vs Llama: Phi weights can reduce hardware cost because the models are smaller, but the cost comparison depends on your target runtime. If you already have GPU capacity for Llama, Phi may not save much. If you are aiming for CPU, NPU, laptop, or edge deployment, it can change the economics completely.
Limitations: Phi is not a replacement for Llama when you need a general-purpose large model with broad community fine-tunes and many deployment recipes. It is also not the right model if your workload depends on maximum multilingual breadth or huge context.
The most common Phi mistake is comparing it to Llama on tasks that require a large general model and then dismissing it. A better test is constrained: can Phi solve the narrow job locally with lower memory, lower latency, and fewer moving parts? If yes, it may be the more product-friendly choice even when a larger model wins broad benchmarks.
Best for: Phi is best for small local reasoning, educational apps, device-side assistants, and prototypes where latency and footprint matter more than frontier breadth. Not the right fit if your team needs a Llama 405B-class open-weight baseline.
Get started with Microsoft Phi.
AI2 OLMo
OLMo is the most principled alternative in this list. It is not here because it is the easiest production choice. It is here because "open weights" is not enough for researchers, auditors, and teams that need to understand how a model was built.
What AI2 OLMo solves vs Llama: Transparency stack: Ai2's OLMo 2 page says open weights alone are not enough and points to open training data, open-source training code, reproducible recipes, transparent evaluations, intermediate checkpoints, and model artifacts. The OLMo 2 blog describes the release as weights, data, code, recipes, intermediate checkpoints, and instruction-tuned models.
Pricing vs Llama: OLMo is not a cheap hosted API play. The value is auditability. You may spend more engineering time than you would with Llama, but you gain a cleaner research story and a stronger basis for reproducibility.
Limitations: OLMo is less polished as a commercial platform than Llama, Mistral, or hosted APIs. You may need more internal ML expertise, and raw performance may not beat the best open-weight or closed models for every production workload.
OLMo is also a useful sanity check for every "open source AI" claim in your shortlist. If a vendor only releases weights, ask what is missing: data, code, recipes, intermediate checkpoints, eval details, or post-training artifacts. You may still choose the vendor, but the conversation becomes precise instead of semantic.
Best for: OLMo is best for universities, policy teams, model auditors, reproducibility research, and companies that need to inspect more than weights. Not the right fit if your only goal is fast product deployment with minimal ML operations.
Get started with AI2 OLMo.
GLM / Z.ai
GLM is the supplier-diversity pick. If your model strategy currently depends on Meta plus one other lab, GLM gives you another open-model ecosystem to test, especially for coding-agent and general assistant workloads.
What GLM / Z.ai solves vs Llama: GLM's strongest switching reason is optionality. It broadens the vendor map beyond the Meta, Alibaba, Google, Mistral, and DeepSeek clusters. Recent GLM coverage has emphasized permissive open releases and strong coding-agent positioning, which makes it worth a controlled eval when your team wants more than one non-Meta open-weight route.
Pricing vs Llama: GLM can be evaluated through hosted platforms before any self-hosted deployment. That lets you compare output quality, latency, and cost against Llama without first committing to a new inference stack. If you later self-host, the cost profile moves back toward hardware and operations.
Limitations: Z.ai's branding, model naming, provider availability, and release cadence can be harder for enterprise buyers to track than Meta or Google. Verify the exact model terms and do not rely on community summaries for commercial rights.
GLM becomes more persuasive if your product already needs a model router. In that architecture, you are not asking one model family to replace everything. You are asking GLM to compete for coding, agent, or long-context jobs where it can win. ToolWorthy tracks related GLM releases such as GLM-5 and GLM-5-Turbo.
Best for: GLM / Z.ai is best for teams building a diversified open-model router, coding-agent experiments, or China-market model coverage. Not the right fit if your procurement team needs a long-established Western enterprise vendor.
Get started with GLM / Z.ai.
OpenAI GPT-OSS
OpenAI GPT-OSS is the controversial inclusion because many teams think of OpenAI as the opposite of Llama: hosted, closed, and API-first. The reason to include it is practical. OpenAI now offers gpt-oss-120b and gpt-oss-20b as open-weight reasoning models under Apache 2.0 plus the gpt-oss usage policy, so some U.S. teams may prefer that vendor route even if it is not as community-native as Llama.
What OpenAI GPT-OSS solves vs Llama: It gives teams a way to evaluate open-weight deployment while staying close to OpenAI tooling, developer habits, safety expectations, and procurement familiarity. That matters when the internal objection to Llama is less about model quality and more about vendor governance.
Pricing vs Llama: Pricing depends on whether you use hosted OpenAI models, open-weight deployments through a provider, or internal infrastructure. The key comparison is not "OpenAI is cheaper." It is that familiar tooling can reduce migration and review cost for organizations already standardized on OpenAI.
Limitations: GPT-OSS should not be treated as equivalent to OpenAI's hosted frontier models. Verify the exact release, license, training disclosures, and allowed deployment modes. If your reason for leaving Llama is maximal openness, OLMo or Apache-licensed releases may be cleaner.
The best GPT-OSS buyer is not the local-model enthusiast. It is the organization that already trusts OpenAI, already has internal SDK patterns around OpenAI-style APIs, and wants an open-weight escape hatch without changing its vendor-review story too much. That is a real use case, but it is different from choosing the most open or cheapest model.
Best for: OpenAI GPT-OSS is best for teams that want an open-weight path inside a familiar U.S. vendor ecosystem. Not the right fit if you need the strongest local community or fully open training data.
Get started with OpenAI GPT-OSS.
NVIDIA Nemotron
Nemotron is the infrastructure-native alternative. It makes the most sense when the model decision is tied to NVIDIA hardware, NIM, DGX Cloud, inference optimization, or enterprise AI platform work.
What NVIDIA Nemotron solves vs Llama: Nemotron reduces the gap between model choice and production serving. NVIDIA has positioned the family around optimized inference and open model collaboration, including its 2026 Nemotron coalition work. If your organization already buys NVIDIA infrastructure, a model stack designed for that environment can be easier to operationalize than a generic Llama deployment.
Pricing vs Llama: Nemotron can be cheaper than a poorly optimized Llama deployment on the same hardware and more expensive than a simple hosted API. The real comparison is throughput per dollar on your actual NVIDIA stack, not headline token price.
Limitations: Nemotron is not as culturally central as Llama in the open-weight community. License and commercial terms can vary by model and service path, especially if you use NIM or managed infrastructure.
Nemotron should be judged inside the stack where it is meant to run. If your team is already using NVIDIA infrastructure, compare throughput, batch behavior, latency, and operational support against Llama on the same hardware. If your team is not already on that stack, Nemotron may be less compelling than a simpler API or a community-dominant local model.
Best for: NVIDIA Nemotron is best for enterprise AI teams already invested in NVIDIA hardware and serving software. Not the right fit if you want the broadest local hobbyist ecosystem or the cheapest hosted API.
Get started with NVIDIA Nemotron.
Honorable Mentions
Claude is not a Llama replacement if open weights are required, but it is often the better product choice for reasoning, writing, analysis, and coding assistance. Use it when the real migration reason is quality and reliability, not model ownership. Start with Claude.
Gemini is the managed Google route when Gemma is too small or too self-directed. It fits teams that want multimodal support, long context, Google Cloud integration, and a vendor-managed model lifecycle. If you are comparing end-user assistants rather than model infrastructure, pair this with the broader AI chatbot comparison. Start with Gemini.
Cohere Command belongs on the shortlist for enterprise RAG and retrieval-heavy workflows. It is less compelling if you want downloadable weights, but more compelling if your migration problem is search, grounding, and enterprise deployment. Start with Cohere.
Together AI is a practical bridge for teams that want open models without owning GPUs. It can host many model families, letting you compare Llama, Qwen, Mistral, DeepSeek, and others behind a provider layer. Start with Together AI.
Fireworks AI plays a similar role for fast open-model serving. It is a good evaluation path before deciding whether a Llama alternative deserves internal infrastructure. Start with Fireworks AI.
Migrating from Llama - A Practical Guide
Model and Data Migration
Start by separating the model from the system around it. A Llama deployment usually has prompt templates, model-specific system messages, safety filters, eval scripts, adapters, retrieval settings, quantization choices, caching behavior, and provider assumptions. If you change only the model name, the migration will look easier than it is for the first week and messier than expected by week three.
For a hosted API move, create a dual-stack model router. Keep Llama as the baseline, add DeepSeek or Mistral for a small percentage of traffic, and log outputs against the same eval set. Measure cost per successful task, not cost per token. A model that uses twice as many tokens to finish the same task may be less cheap than its rate card suggests.
For an open-weight move, capture the exact model card, license, quantization, runtime, context length, and hardware profile. "Qwen worked well locally" is not a reproducible migration note. "Qwen3 30B A3B GGUF, Q4_K_M, llama.cpp version X, 32K context, Mac Studio M-series, average Y tokens/sec on these prompts" is useful.
For fine-tuned Llama systems, do not assume adapters transfer cleanly. Some adapters, datasets, or prompt formats may need to be rebuilt. Put your highest-value eval examples first: refusal behavior, domain vocabulary, tool-use schemas, retrieval citations, JSON validity, and long-context failure cases.
A practical migration packet should include the current Llama model and version, inference runtime, quantization, hardware profile, average and p95 latency, token cost or hardware cost, context settings, prompt templates, retrieval configuration, safety policy, and the top 50 failure examples from production. Without that packet, teams tend to compare a carefully tuned Llama stack against a fresh alternative and misread the result. The alternative may be better, but it still deserves the same tuning budget before the final decision.
Do a separate license packet. Save the official license URL, model card, acceptable-use policy, provider terms, and any regional restrictions for the exact model you plan to use. Screenshots and community summaries are not enough for a production decision. If you use a hosted provider for an open model, you need both layers: the model's license and the provider's terms for data handling, retention, rate limits, and acceptable use.
Learning Curve by Alternative
Near-zero migration options are hosted APIs and serving providers: DeepSeek, Mistral API, Together AI, and Fireworks AI. They still need security review and evals, but they do not require you to become an inference team before seeing output.
Medium migration options are Qwen, Gemma, GLM / Z.ai, Phi, and Nemotron. You can often test them quickly, but production quality depends on model size, runtime, quantization, provider choice, and hardware.
High migration options are Kimi and OLMo. Kimi is high effort because the interesting versions are large and agent-oriented. OLMo is high effort because the point is transparency and reproducibility, which asks more from your team than a normal product integration.
Pricing Brackets vs Llama Self-Hosting
Free or open weights with hardware cost: Qwen, Gemma, Phi, OLMo, Mistral open models, GLM, Kimi, and Nemotron. The download may be free, but production is not. Count GPU hours, storage, monitoring, staff time, eval maintenance, rollback paths, and incident response.
Cheap hosted API: DeepSeek is the obvious first test. It is especially strong for long-context and agent-style workloads where infrastructure overhead would otherwise dominate.
Enterprise managed: Mistral, Cohere, Gemini, Claude, and some NVIDIA routes. These can look expensive per token and cheaper in practice when vendor support, data processing, uptime, procurement, and security controls matter.
Provider route: Together AI and Fireworks AI. This is often the fastest way to compare multiple open model families without turning your model evaluation into a hardware purchase.
The pricing comparison should always end with a switching-cost line. If DeepSeek saves $2,000 per month in inference but requires six weeks of security review and router work, the first-year payback may be weak. If Qwen removes a license blocker that is delaying a customer contract, the business case can be strong even when infrastructure cost stays similar. Alternatives decisions are rarely pure model decisions; they are cost, risk, and time-to-ship decisions.
Best Llama Alternatives by Use Case
If Your Reason Is "Everyone keeps recommending Qwen now"
Test Qwen first, DeepSeek second, and Gemma third. Qwen is the closest answer when your team wants local weights, permissive model-card language, coding momentum, and multilingual coverage. DeepSeek is the API counterweight if your team realizes the actual goal is cheap inference rather than local control. Gemma is useful when the problem is smaller and the model needs to run on modest hardware.
Use the same local runner, hardware, and context settings when possible. A Qwen result from a carefully selected quant should not be compared against a poorly chosen Llama quant. Track tokens per second and task success together; a model that is 10% better but half as fast may not be better for an interactive coding assistant.
If Your Reason Is "The DeepSeek API is cheaper than my GPU plan"
Start with DeepSeek and build a simple cost-per-task benchmark. Compare it against your current Llama self-hosting cost, not a theoretical token price. If procurement dislikes DeepSeek, test Mistral API or GLM through a provider. If the workload is sensitive, keep Llama as the fallback while you evaluate logs and retention terms.
The useful spreadsheet has one row per task type: summarize a long document, run a code edit, answer a retrieval question, classify a ticket, call tools, generate JSON, and handle a refusal-sensitive prompt. Put input tokens, output tokens, retries, latency, and human corrections in separate columns. This reveals whether "cheap tokens" are still cheap after retries and verbose outputs.
If Your Reason Is "Legal wants Apache 2.0"
Look at exact Apache/MIT releases from Qwen, Mistral 3, OLMo, Phi, GLM/Z.ai, and OpenAI GPT-OSS before writing anything into a compliance document. Review Gemma separately under Google's Gemma Terms instead of grouping it with standard permissive licenses. The important point is not that every model from those families is always Apache 2.0. The point is that standard permissive licenses exist in those ecosystems and can be easier to approve than the Llama Community License.
Ask legal what it actually needs. Some teams need standard redistribution rights. Some need patent comfort. Some need permission to fine-tune. Some need the right to use outputs to train another model. A model can be "open" in a community sense and still fail one of those requirements.
If Your Reason Is "We are deploying in Europe"
Mistral should be on the first shortlist because it gives you a European vendor conversation. Gemma and Qwen may also work depending on model terms and data handling. Be careful with Llama 4 multimodal use. The clause is nuanced, and end-user use is different from license rights for EU-domiciled individuals or EU-headquartered companies, but the nuance itself can be enough to delay procurement.
For EU deployment, write down three separate questions: where the company is based, where the end users are, and where the model or API provider processes data. Those questions can lead to different answers. A legal review that only asks "Is the model open?" is not precise enough.
If Your Reason Is "I need a small model, not a giant MoE"
Test Gemma, Phi, and smaller Qwen variants before trying to shrink a larger Llama model into an edge footprint. Smaller models are not just cheaper. They are easier to test, ship, cache, update, and explain to non-ML stakeholders. If your target device is a laptop, phone, NPU, or small cloud instance, the best Llama alternative may be a smaller family by design.
For edge work, run failure tests on the actual target device. A model that looks fine on a developer workstation can miss latency, memory, or thermal constraints on the device that customers use. Also test update size and rollback behavior; a model swap that is easy in the cloud can be painful in a deployed fleet.
If Your Reason Is "I do not trust Meta's future openness"
Do not replace one single-vendor dependency with another. Build a two-lane eval: one open-weight route such as Qwen, Mistral, OLMo, GLM, or Gemma, and one hosted route such as DeepSeek, Claude, Gemini, or Cohere. The goal is not ideological purity. It is making sure a future Meta roadmap change does not force a rushed migration.
The healthiest architecture is usually boring: a baseline model, one fallback model, one cheap route for low-risk tasks, and clear eval gates for moving traffic. If Meta's roadmap stays open, you still benefit from better routing. If it changes, you already have a tested exit path.
How to Choose the Right Llama Alternative
-
Diagnose the actual reason you are leaving Llama. If the answer is license, start with Qwen, Mistral, OLMo, and Gemma. If the answer is cost, start with DeepSeek and provider-hosted open models. If the answer is local hardware, start smaller before going bigger.
-
Test one hosted model and one open-weight model on your own eval set. Public benchmarks are useful for discovery, but your eval should include the prompts, documents, tools, JSON schemas, refusal cases, and latency targets that actually matter.
-
Verify license, region, and pricing before architecture decisions. Read the exact model card, official price page, and provider terms. Do not use a community thread as the final source for commercial rights.
-
Run a two-week dual-stack period before removing Llama. Keep Llama live as the baseline, route a limited percentage of traffic to the alternative, compare task success, cost, latency, user corrections, and failure modes, then decide with logs rather than vibes.
During that two-week period, do not only watch aggregate win rate. Segment by task type, language, document length, customer tier, safety category, and tool-use path. Model migrations often hide regressions inside one segment while the average looks fine. A model that is better for English coding prompts may be worse for multilingual support tickets or structured extraction.
Decide rollback criteria before the test starts. Examples: JSON validity drops below target, p95 latency increases by more than 30%, human correction rate rises, retrieval citations become less faithful, or a compliance-sensitive refusal case fails. Clear rollback criteria keep the migration from becoming a debate about favorite models.
A useful evaluation matrix has five columns. First, task success: did the model solve the job without human repair? Second, operational cost: what did the task cost after retries, cache misses, serving overhead, and staff time? Third, control: can you run it offline, fine-tune it, inspect enough of the release, and move providers if needed? Fourth, risk: does the license, vendor location, regional policy, data retention, or acceptable-use language create a blocker? Fifth, migration cost: how many prompts, tools, evals, adapters, and product assumptions must change?
Score each alternative against those five columns, not against Llama in the abstract. DeepSeek may win cost and migration cost while losing control. Qwen may win license and local momentum while requiring more inference work. Mistral may win procurement and support while not being the cheapest. OLMo may win transparency while losing product polish. Gemma and Phi may win deployment footprint while not replacing a large general model. This matrix keeps the decision honest because every model has a tradeoff column.
If two models tie, choose the one that reduces future optionality risk. A model that works through multiple providers, supports your eval harness, has clear terms, and can be replaced later is often better than a slightly stronger model that forces you into one vendor or one hardware assumption. The most resilient 2026 architecture is model-agnostic enough that no single lab's roadmap becomes your product roadmap.
For rollout, use three gates. The first gate is offline evaluation: fixed prompts, fixed documents, fixed scoring, and reproducible settings. The second gate is shadow traffic: the alternative receives real production inputs but does not answer users. The third gate is limited live traffic: 1-5% of low-risk requests, then a gradual increase only if the failure metrics stay inside the rollback thresholds. That sequence feels slow, but it is faster than cleaning up a public model regression.
Avoid four common mistakes. The first is testing only happy-path prompts. If every prompt is clean, English, short, and well structured, almost every modern model looks good. Add messy documents, ambiguous user requests, mixed-language inputs, adversarial instructions, tool failures, malformed JSON requests, and long-context edge cases. The second mistake is ignoring prompt rewrites. A prompt tuned for Llama may underperform on Qwen, DeepSeek, or Mistral, so give each serious candidate a fair prompt pass before rejecting it.
The third mistake is treating provider latency as model latency. A slow result may be caused by the provider, region, queueing, context size, cache behavior, or your own router. If a model looks promising but slow, test it through at least two serving paths before deciding the model itself is the problem. The fourth mistake is counting only engineering preference. The winning model must satisfy the people who will live with the decision: legal, security, finance, support, product, and the engineers on call when inference fails.
Finally, keep a written "why not Llama?" note next to the decision. Six months later, when the next Llama release arrives or the alternative changes pricing, that note tells you what to re-evaluate. If the original reason was license, a new benchmark does not settle the question. If the original reason was cost, a price change does. If the original reason was regional deployment, new terms or regulatory guidance may matter more than model quality. Good model strategy is not picking a permanent winner; it is preserving the ability to change for the right reason.
One more practical rule: never migrate the hardest workload first. Start with a low-risk, high-volume task where the result is easy to score, such as summarization, classification, draft generation, or internal Q&A. That gives you cost and latency data without exposing the business to the riskiest failure modes. After that, move to tasks with tools, retrieval, and customer-visible outputs. The final stage should be the tasks that combine long context, compliance sensitivity, tool calls, and direct customer impact. If a Llama alternative cannot win the easy workloads, it is not ready for the hard ones. If it wins the easy workloads cleanly, you have evidence, not just enthusiasm, for the next rollout gate.
Keep the comparison alive after launch. Model families move quickly, and a June 2026 answer may be different by the next major release. Schedule a quarterly re-evaluation with the same eval set, the same cost model, and the same license checklist. That cadence prevents two bad outcomes: staying on Llama because nobody wants to reopen the decision, or chasing every new model because the team never wrote down what "better" means. The right Llama alternative is not the newest model; it is the one that keeps winning your documented decision.
Frequently Asked Questions
What is the best free alternative to Llama?
For hosted work, DeepSeek can be the cheapest practical first test even though it is not "free." For production teams, the best free model is the one whose total operating cost stays low after hardware, monitoring, and staff time are included.
Is Qwen better than Llama for local coding?
Use real repository tasks: explain a module, edit a function, write a migration, fix a failing test, generate typed JSON, and answer questions that require cross-file context. Coding-model preferences change quickly, so your local eval is more reliable than a one-week-old comment thread.
Which Llama alternative has the cleanest commercial license?
The cleanest license is also the one your downstream customers accept. If you redistribute models, build derivative models, or use outputs for training, ask those questions explicitly before choosing.
Should European companies avoid Llama 4 multimodal models?
Text-only Llama models and multimodal Llama models may have different practical risk profiles. Do not collapse them into one rule. If your use case is multimodal and EU-facing, consider Mistral, Gemini, Gemma, or another provider while counsel reviews the exact Llama clause.
Is DeepSeek cheaper than self-hosting Llama?
The break-even point depends on utilization. If your GPUs are idle half the day, hosted APIs can win quickly. If you already have high utilization, specialized serving expertise, and strict data-control needs, self-hosting may still be cheaper and safer.
Which Llama alternative is best for edge devices?
Do not use one desktop benchmark as the final edge decision. Test cold start, sustained load, offline behavior, update size, and degraded-network cases on the actual device class.
Is Meta still committed to open Llama-style models?
That second supplier does not need to replace Llama everywhere on day one. It only needs to be tested deeply enough that a future roadmap change is inconvenient rather than existential.
Should I use hosted APIs instead of open weights?
The strongest 2026 pattern is hybrid: one managed API for fast product delivery, one open-weight model for control, and a shared eval harness that keeps both honest.
Get ToolWorthy Weekly
New AI tools, practical guides, and selected AI signals in one weekly brief.
Discover More AI Tools
Explore our comprehensive directory of AI tools, carefully curated and reviewed by experts to help you find the perfect solution for your needs.